芬兰大学突破AI瓶颈:光速计算时代来临?
创始人
2025-11-26 07:15:07
0次
近日,芬兰阿尔托大学的研究团队展示了一种名为“并行光学矩阵-矩阵乘法器”(POMMM)的新型光学计算架构,该技术有望解决人工智能(AI)模型训练和执行中的核心瓶颈问题。POMMM通过利用单次相干光的传播过程完成矩阵与矩阵的乘法运算,其核心原理是将数字张量编码为光的相位和振幅,并通过透镜组实现傅里叶变换,最终以干涉图像的形式被高速探测器捕捉。这种算术过程在光的“飞行”中瞬间完成,无需电子环路或内存读取,实现了物理层面的“自然同步计算”。
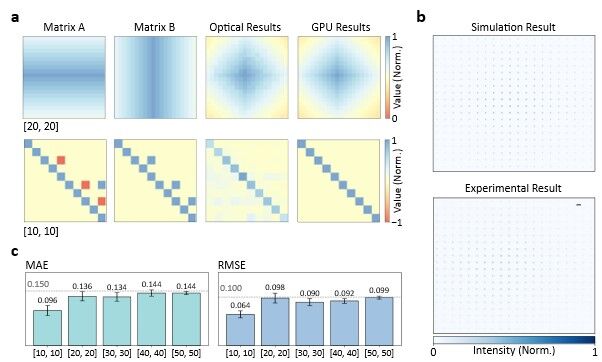
研究团队基于现成的光学元件搭建了原型机,并在标准光学平台上耗时六个月完成组装。测试结果显示,对于最大50x50的矩阵,该原型的平均绝对误差(MAE)低于0.15,归一化均方根误差(RMSE)则保持在0.1以下,满足许多边缘推理应用的需求。尽管当前原型机的能效仅为2.62GOP/J,远低于顶尖GPU,但其运算延迟可达纳秒级,远胜于电子计算的微秒级。研究团队已在GitHub上开放了所有代码和数据,以加速技术验证和社区发展。
研究人员指出,探测器的动态范围和校准漂移是目前需要攻克的难题。未来的技术路线图非常清晰,通过将空间光调制器和探测器阵列等关键部件集成到低损耗的氮化硅光子芯片上,能效有望实现百倍提升。团队预测,集成了专用光子芯片的原型机有望在三年内问世,预计能将能效提升至300GOP/J,远超电子GPU目前约30GOP/J的能效瓶颈。不过,考虑到封装、温控和激光器集成等工程挑战,距离实现大规模量产可能还需要五年以上的时间。

相关内容
热门资讯
2026广州戏水季开幕!主会场...
7月12日上午,2026年广州市“盛夏潮玩森康养·清凉广州逐浪狂欢”戏水季活动在主会场白江湖森林公园...
“有情有义·烟火潮汕”文旅品牌...
羊城晚报全媒体记者黎存根、蚁璐雅报道:7月13日,“有情有义·烟火潮汕”——潮汕三市旅游联盟暑期旅游...
多所高校宣布停招学硕 研究生招...
原标题:多所高校宣布停招学硕,研究生招生考试改革纵深推进近年来,研究生招生改革持续深入推进。国务院近...
广东女企业家组团叩响港交所 大...
羊城晚报全媒体记者 莫谨榕7月9日,7家企业集体在港交所鸣锣上市,创下今年以来港交所单日IPO数量之...
广州楼市上半年成交超8.4万套
羊城晚报全媒体记者徐炜伦报道:近日,广州市房地产中介协会、广州中原研究发展部等专业机构陆续发布202...
暴雨来袭!多场景防汛避险指南
制作:王宇峰 刘珂君 岳小乔 贾雪 胡洋上佳 董文阳
继续驰援广西!广州已捐赠(认捐...
文/羊城晚报全媒体记者 高焓 通讯员 林甄茹 林丽玲图/通讯员供图近期,受今年第10号台风“美莎克”...
长江十年行丨重塑长江:跨越18...
当我们从深空俯瞰神州大地,一条孕育华夏文明的超级水系,正以磅礴之势劈开群山,奔涌向海。这就是长江。千...
开“新”WAIC丨9个关键词,...
2026世界人工智能大会(WAIC)暨人工智能全球治理高级别会议将于7月17日至20日在上海举行作为...
收录3.9万名烈士英名!广东省...
文、图/羊城晚报全媒体记者 侯梦菲 通讯员 叶婷婷 刁晓玲7月13日,致敬南粤丰碑——《广东省烈士英...
从老渔港到“美丽庭院”省级特色...
南海之滨,百安半岛如一弯新月,三面枕海,静卧于深圳市深汕特别合作区的东南角。这里曾是伴随潮声醒来的老...
上半年私募备案大增超45% 1...
羊城晚报记者 莫谨榕今年上半年,私募发行热度持续升温。私募排排网数据显示,截至6月30日,上半年全市...
不只有长隆!广州这些藏在森林里...
文/羊城晚报全媒体记者 马灿图/受访者提供7月12日,2026年广州市“盛夏潮玩森康养·清凉广州”逐...
“我背你”——抚顺洋湖村的暖心...
7月10日傍晚,天色渐沉,山雨欲来的闷热,压得树梢一动不动。抚顺县上马镇洋湖村的地质灾害点警示牌旁,...
文学之树常青,长篇小说山海传奇...
文/羊城晚报全媒体记者 卢佳圳 通讯员 黄三笑 陈映琼图/李剑锋7月12日,由广州市黄埔区作家协会主...
机构:广州楼市上半年成交超8....
文、图/羊城晚报全媒体记者 徐炜伦近日,广州市房地产中介协会、广州中原研究发展部、克而瑞等专业机构陆...
【讲习所·中国与世界】习近平:...
【本期导读】7月10日,中国国家主席习近平在北京同来华进行国事访问的纳米比亚总统恩代特瓦举行会谈,就...
雨林为幕,歌声为桥:中意青少年...
中新网海南五指山7月12日电 题:雨林为幕,歌声为桥:中意青少年相约五指山“通过音乐交到新朋友”作者...
关口前移、预防为先——多地强化...
近期,极端天气多发频发,防汛形势严峻复杂。记者在采访中了解到,多地强化监测预警和应急救援准备,扎实做...
AI中国绘开局丨半年创新答卷!...
2026年已过半程回望这半年新质生产力拔节生长融入千行百业从田间地头的智慧农田到生产线上的数字孪生工...