AI临床诊断失误率超80%,早期鉴别诊断成短板
创始人
2026-04-18 10:38:35
0次
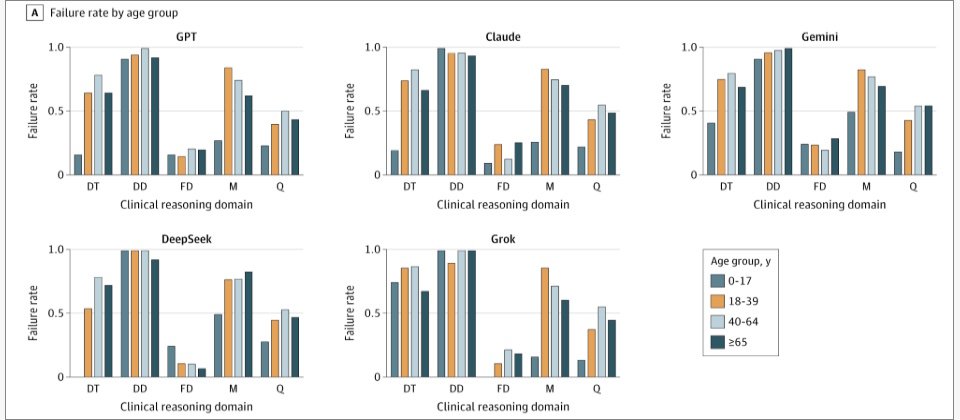
4月17日,美国医学会旗下期刊JAMA Network Open发表的研究指出,当前的大型语言模型(LLMs)在临床推理领域存在显著不足,尤其是在早期鉴别诊断阶段,错误率超过80%。研究团队对GPT-5、Claude4.5Opus等21款主流大模型进行了评测,模拟了完整的医疗决策流程,包括鉴别诊断、检查选择、最终诊断、治疗管理等五个阶段。
评测结果显示,各模型在不同诊疗阶段的表现存在差异,且不均衡。在“最终诊断”和“治疗管理”环节,AI的准确率相对较高,而在“检查选择”和其他推理能力方面处于中等水平。然而,在早期的“鉴别诊断”阶段,AI的表现最差,错误率普遍超过80%,表明模型在判断病人具体疾病时常常出现误判。研究分析认为,AI在信息相对完整的情况下更擅长给出答案,但在信息不足、需要逐步推理的早期阶段,容易过早收敛到单一结论,导致难以直接应用于临床决策。相比之下,临床医生在初期会保留多种可能性,并随着检查结果和信息积累不断修正判断,最终确定患者的具体疾病。
相关内容
热门资讯
大众集团大刀阔斧:车型阵容砍半...
7月10日,大众集团宣布了一项大规模收缩计划,该计划将即刻生效。根据计划,集团旗下各品牌的车型阵容最...
大众汽车全球裁员或达12万,德...
7月10日,德国大众汽车集团在监事会会议上讨论了新一轮降本计划,可能包括裁减岗位和调整德国工厂布局。...
“红棉创新先锋榜”助企创效超2...
文、图/羊城晚报全媒体记者 江皓轩 通讯员 荔宣2026年7月9日下午,广州市荔湾区2026年非公党...
广建鼎新集团493名人员抵达广...
受今年第10号台风“美莎克”残余环流、西南季风及天文潮共同影响,广西多地遭遇持续强降雨,部分区域电力...
外媒:中国共产党领导中国人民创...
国际在线专稿:斯里兰卡《岛报》近日刊登了斯里兰卡政治学者、前外交官达延·贾亚提莱卡(Dayan Ja...
广西多地遭遇持续性极端强降雨 ...
受今年第10号台风“美莎克”影响,广西多地遭遇持续性极端强降雨,引发系列灾情。南宁、贵港多座水库发生...
视频丨日本学者:日元贬值红利正...
日本民间调查机构帝国数据库公司7日公布的最新数据显示,今年上半年因物价上涨导致的企业破产共计556起...
习近平党建思想系列解读九丨高素...
《以理服人丨习近平党建思想系列解读》第九期洪向华:中共中央党校(国家行政学院)科研部副主任习近平党建...
无人机搜救、空中通信保障 科技...
这几天,多方力量驰援广西,通过夜间照明、无人机搜救、重载物资投送、空中通信保障等手段,为防汛救灾打通...
重走西行漫记之路② | 时代...
1936年7月,美国记者埃德加·斯诺突破重重封锁,前往陕北地区采访,写成《红星照耀中国》(《西行漫记...
行进中国|“西藏造”接出高原新...
雅鲁藏布江支流畔,西藏山南市扎囊县,海拔3600多米的中车山南清洁能源装备产业园车间内机器低鸣。藏族...
活力中国调研行|支撑完成3万个...
高级记者 邹娟 张呈君 见习记者 洪旭东上海光源。 本文图除署名外均为 上海光源 供图如果科学探索本...
售卖不合规海外保健品,代购被判...
海外代购抗疲劳胶囊,吃了反而入睡更困难,其中还有成分竟然未获生产许可!当消费者海外代购保健食品,买到...
大湾区涉外审判人才研修班在广州...
文/羊城晚报全媒体记者 鄢敏7月6日至8日,由广东省高级人民法院与香港国际法律人才培训学院联合主办的...
肇庆封开:电商培训孵出“新农人...
文/羊城晚报全媒体记者 周聪图/受访者供图盛夏时节,广东省肇庆市封开县麒麟李迎来丰收季,一颗颗饱满清...
“圈”出家门口的幸福——重庆市...
服务业贯通生产生活,关乎千行百业、千家万户。“十五五”开局起步,一系列部署密集展开,推进服务业扩能提...
“全球作家写广东”开启采风 7...
来自APEC成员经济体的7名作家将在广东走访近两个月,汲取创作养分羊城晚报讯 记者党学为报道:7月8...
阿根廷队的“超级逆转”引发“超...
一场跌宕起伏的超级逆转,引发的却是超级争议。阿根廷3比2绝杀埃及的美加墨世界杯1/8决赛,终场前,埃...