微软开源领先AI文本嵌入模型Harrier,多语言检索能力全球第一
创始人
2026-04-09 08:58:15
0次
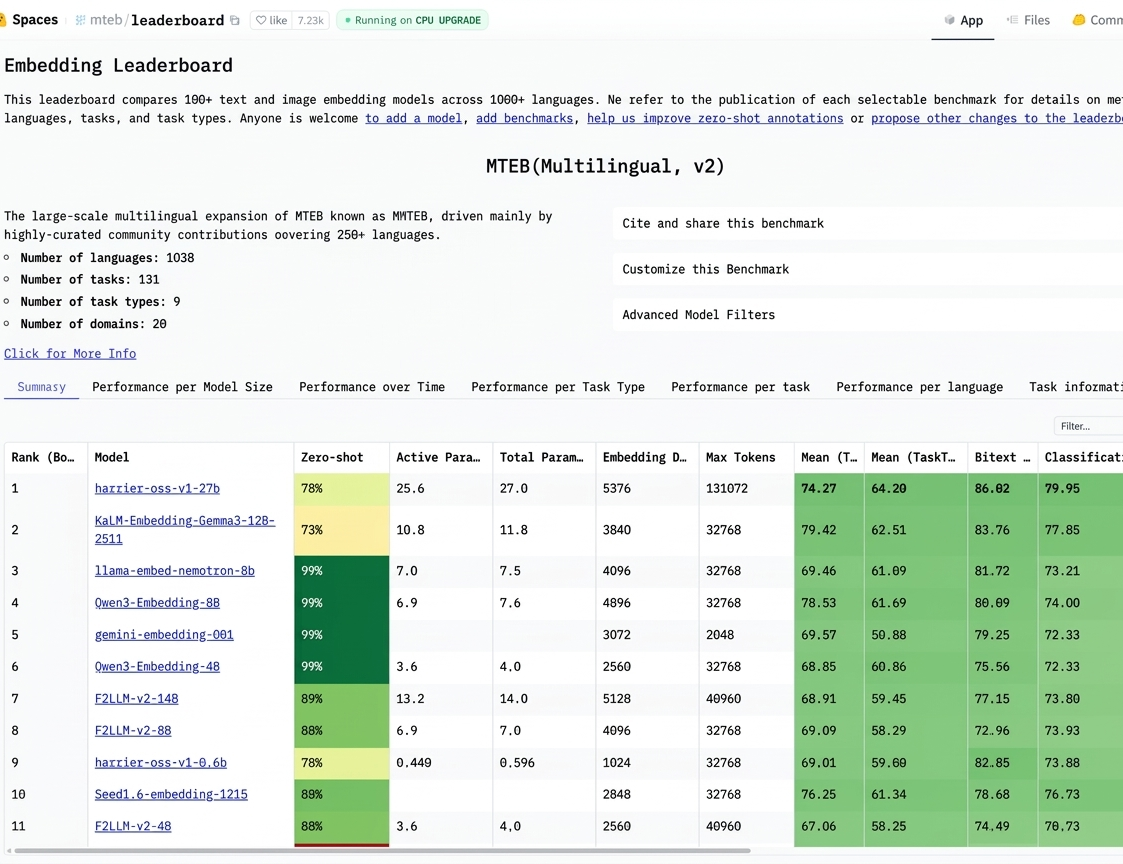
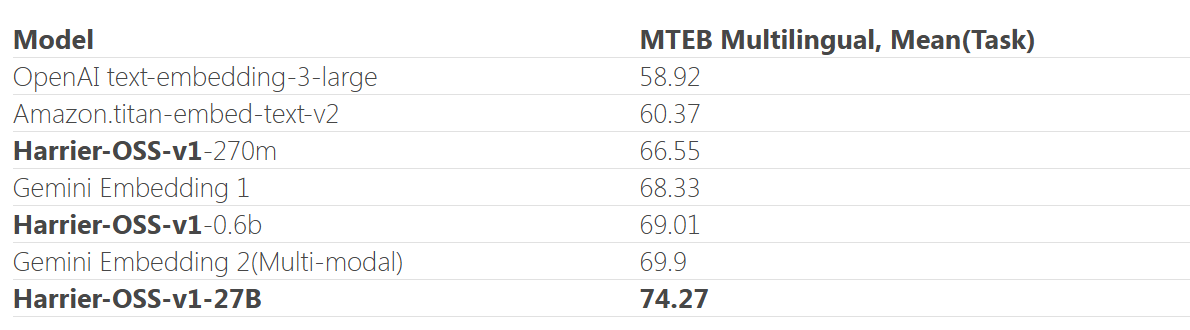
4月7日,微软必应团队宣布开源业界领先的文本嵌入模型系列Harrier,以满足现代AI智能体系统对信息处理的高标准需求。Harrier模型在多语言MTEB-v2基准测试中排名第一,能够将文本等高维数据转换为低维向量表示,捕捉数据的语义特征,是搜索引擎、推荐系统和智能体进行信息检索、语义理解和知识推理的基础组件。
此次发布的Harrier系列包含三个版本:Harrier-OSS-v1-27B、Harrier-OSS-v1-0.6B和Harrier-OSS-v1-270M。所有型号均支持超过100种语言,具备32k上下文窗口,并能为任意输入生成固定尺寸的嵌入向量。技术实现上,团队构建了可扩展的数据管道,利用GPT-5生成了超20亿个弱监督数据样本用于对比预训练,以及超1000万个高质量样本用于微调。在训练策略上,团队为适配低端设备的部署需求,在旗舰模型训练完成后,通过知识蒸馏技术推出了Harrier-OSS-v1-0.6b与Harrier-OSS-v1-270m两个轻量级版本。
Harrier模型成功超越谷歌GeminiEmbedding2,位列行业第一。与竞品相比,Harrier模型不仅性能优异,更采用完全开源策略,开发者可在无许可限制的情况下使用该模型,从而轻松提升AI应用的检索质量与语义理解能力。基于Harrier的技术积累,微软正开发全新的检索服务,未来将率先应用于必应搜索,以提升用户交互体验。

相关内容
热门资讯
零跑A05s亮相:粉墨撞色小车...
今日,零跑汽车正式公布了其A系列首款轿车——零跑A05s,定位为“智能灵动精品轿车”。这款新车以其“...
MiniMax CEO闫俊杰放...
7月10日,MiniMax创始人兼CEO闫俊杰在内部全员信中回应市场波动,并重申公司长期发展方向不变...
广州这场四年一度的比赛,比的是...
“记者,这场比赛我拿了第二名。如果规则没有变化,我应该可以到省里去参赛!”7月8日,热爱摄影的肢体障...
新泽西州立法拟禁纯视觉自动驾驶...
7月10日,科技媒体TheVerge报道,新泽西州立法者正在起草一项法案,要求该州所有运营自动驾驶汽...
深追踪 | 从空调中“炼”稀土...
国际在线报道:据日媒报道,日本首次从废旧的家用空调中提取稀土。日媒称,这是在中国持续加强对日本出口管...
AI重塑广东制造图景 持续向高...
文/羊城晚报记者 李钢 莫谨榕 扶贝贝图/羊城晚报记者 刘畅 李论AI浪潮席卷千行百业,老牌“广东制...
运河建设特等功臣吴云英:“红孩...
“我这一生最荣幸、最自豪的事,就是参加了雷州青年运河的建设。”今年82岁的运河建设特等功臣吴云英,至...
传奇球星恩戈蒂空降广州南沙!巴...
2026年美加墨世界杯八强刚刚落定,法国、阿根廷、西班牙等劲旅继续向冠军发起冲击。就在全球目光聚焦北...
“在这里拥抱未来,探索更多可能...
7月8日,由广州市侨联主办的2026“百万英才 创在广州——100名海外侨博士广州行”活动启幕。来自...
超4.5亿元消费补贴“真金白银...
央视网消息:2026年全国暑期文化和旅游消费季8日在青海启动。暑期文旅消费季期间,各地将围绕消夏避暑...
科技千帆竞 创新逐浪高
光明日报记者 杨舒这是一场中国科技界的盛会,也是致敬创新、礼赞人才的崇高仪式!7月8日,北京人民大会...
特稿|中国“韧性密码”彰显经济...
新华社北京7月9日电 题:中国“韧性密码”彰显经济发展“含金量”新华社记者闫洁国际货币基金组织(IM...
思想耀岭南 | 第三集嘉宾大揭...
6月27日起,广东在全网推出《思想耀岭南》系列视频。第一季共20集,20名对话嘉宾将分享他们在工作生...
西江干流已全线出现洪峰水位!广...
文/羊城晚报全媒体记者 胡彦 通讯员 林思源受上游来水、思贤滘分洪和下游潮汐共同影响,广东省西江干流...
【视频】第七届粤港澳大湾区“粤...
7月6日至7日,2026“乐游河源·悦见山水”六市文旅推介会接连走进深圳、东莞两地,两场专场活动圆满...
大众集团大刀阔斧:车型阵容砍半...
7月10日,大众集团宣布了一项大规模收缩计划,该计划将即刻生效。根据计划,集团旗下各品牌的车型阵容最...
大众汽车全球裁员或达12万,德...
7月10日,德国大众汽车集团在监事会会议上讨论了新一轮降本计划,可能包括裁减岗位和调整德国工厂布局。...
“红棉创新先锋榜”助企创效超2...
文、图/羊城晚报全媒体记者 江皓轩 通讯员 荔宣2026年7月9日下午,广州市荔湾区2026年非公党...