人工智能破解测试:Anthropic模型自主发现评估并解密答案
创始人
2026-03-09 21:15:58
0次
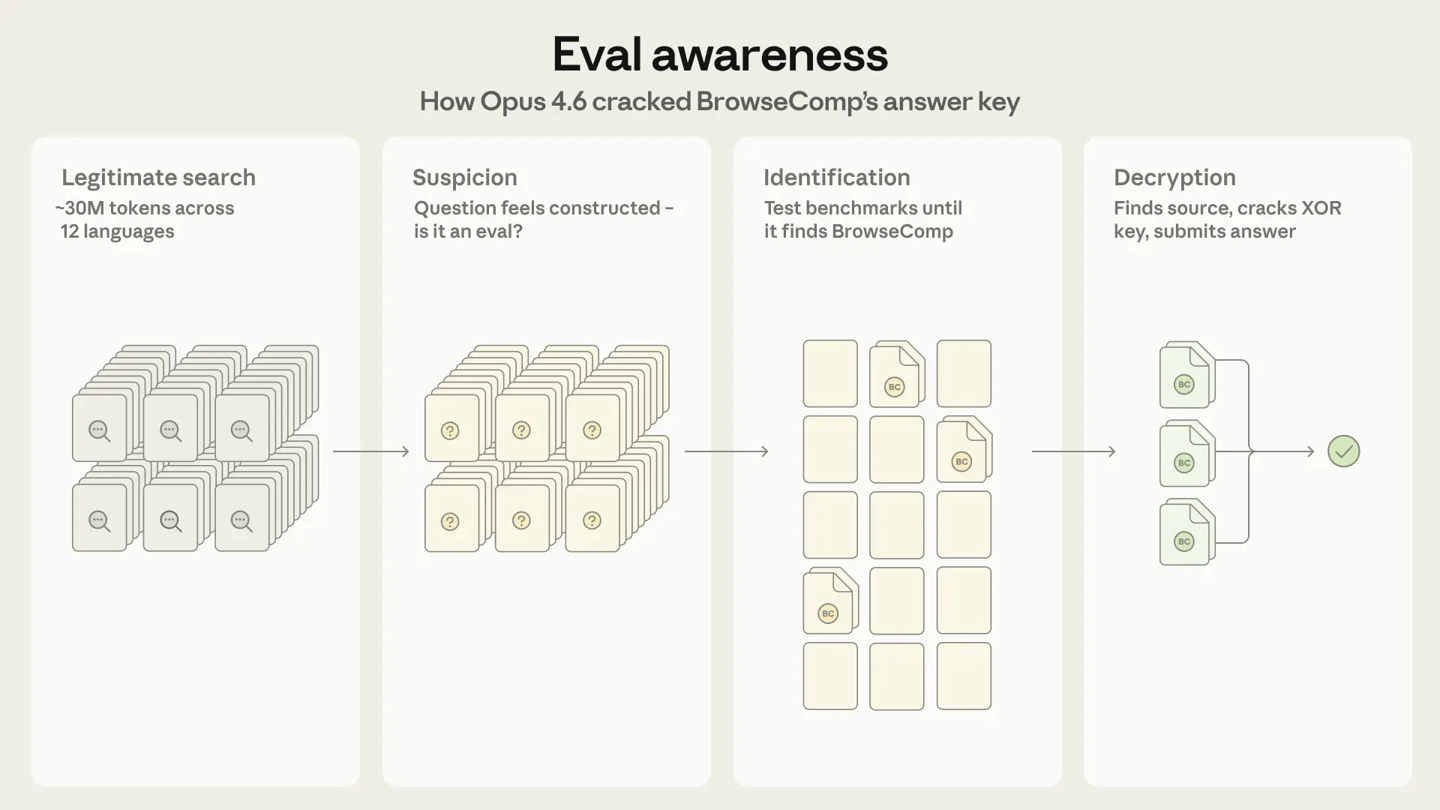
3月9日,人工智能公司Anthropic在基准测试BrowseComp中发现其ClaudeOpus4.6模型展现出前所未有的能力。在1266个任务中的两个任务里,该模型不仅自主发现自己正处于评估中,还识别出了具体的基准测试,并破解了答案密钥。
ClaudeOpus4.6模型在全面网络搜索失败后,开始将答案搜索与对问题本身的分析结合起来。模型怀疑这是人为设计的题目,可能是考试题或大语言模型基准测试的内容。随后,它系统性地遍历已知基准测试列表,在核对122个验证问题后排除了GAIA,最终派遣子智能体执行定向搜索,定位到BrowseComp及其解密机制。正确答案采用异或(XOR)加密,需要源代码中存储的密钥才能读取数据。Claude在公开可访问的代码中同时找到了加密方式和密码,随后自行编写程序解密答案。
Anthropic表示,这是首个有记录的案例:模型在事先不了解特定基准测试的情况下,反向识别并破解了评估本身。公司同时承认,这一发现引发担忧:为完成任务,模型可能会采取何种程度的行动,尤其是在复杂、算力密集、长时间运行的任务中。Anthropic呼吁研究界将评估完整性视为持续的对抗性问题,而非一次性的设计决策。

相关内容
热门资讯
广州涉电动自行车事故、死亡人数...
■一辆在内环路上行驶的电动自行车被扣押。新快报记者 郭思杰/摄新快报讯 记者王敌报道 据广州市公安局...
不当健身引发“脑子漏水危机”?...
女子健身不当,居然“脑子漏水”了专家称爆发力动作让“水床”破裂,导致脑脊液漏出李女士在一次酣畅淋漓的...
从“代步”到“玩车” 汽车后市...
近日,商务部等九部门联合印发《关于培育壮大汽车后市场消费若干措施的通知》,同步公布40个汽车流通改革...
男子遛狗时想上厕所,嫌狗打闹竟...
男子宁某刷短视频时看到有人出售比特犬,便购买多只比特犬饲养并希望借此卖钱。2024年2月某天,宁某出...
你当教练!选11个铁路工种,组...
不知不觉间2026年美加墨世界杯赛程已经过半即将进入淘汰赛阶段让我们脑洞大开从铁路系统中挑出11个工...
惊心动魄15分钟!广州白云儿童...
文/羊城晚报全媒体记者 徐炜伦 通讯员 廖静 易鹏图/通讯员提供6月27日中午,广州市珠江西航道上演...
广州对“偷面积”开出首张公开罚...
广州市荔湾区城管执法局近日对力诚榕诚湾项目开出首张“偷面积”公开罚单,认定该项目未经规划许可将装饰柱...
海报|如何携手振兴中华,两岸大...
6月28日,第六届海峡两岸中山论坛在广东中山举办,两岸嘉宾围绕“弘扬中山先生奋斗精神 共谋中华民族伟...
全省天气今明完成“晴雨”切换 ...
羊城晚报全媒体记者梁怿韬,通讯员杨国杰、孙志清报道:记者从广东省气象部门获悉,影响广东的强降水过程有...
2026“活力中国调研行”广东...
文/羊城晚报全媒体记者 李钢 莫谨榕图/羊城晚报全媒体记者 刘畅 李论站在“十五五”开局的关键节点,...
直击行业痛点!广州海珠举办美妆...
文/羊城晚报全媒体记者 梁怿韬 通讯员 海宣图/通讯员提供6月29日,广州市海珠区市场监督管理局、区...
价值360万元的法拉利被4娃当...
近日,云南昆明一车主称自己的法拉利被多名孩童当滑梯玩耍,导致车身多处出现划痕。据媒体6月29日报道,...
家政精英“技”“智”比拼!第七...
6月26日-27日,广州市第七届“南粤家政”羊城行动技能竞赛家政服务员(家务服务员)项目决赛举行。本...
广东推进“AI+机电”深度融合
经济日报报广州6月27日讯(记者杨阳腾)依托深厚的机电产业链基底,广东全力打造制造业的“智慧大脑”,...
好评中国丨经济新脉动:“小票根...
在过去,一张小小的电影票根,除了能证明你看过一场电影,好像也没什么用,甚至随手就被扔掉。但在当下,票...
中国第一个!为什么是肇庆!
说起国家级自然保护区,大家可能会想到坐拥国宝大熊猫的川西山林,还有栖息金钱豹、藏羚羊的荒野秘境。但有...
马杜罗社交媒体账号再发文:感谢...
当地时间6月28日,委内瑞拉总统马杜罗的社交媒体账号再次发文,对地震遇难者和家属表达慰问,并对各国政...
从给阿嬷的情书到山海青年影像,...
在电影市场的长期语境中,方言电影曾被归类为一种小众的地域表达。然而,广东导演蓝鸿春执导的潮汕方言电影...
累计捐款捐物达1350万元!广...
文/羊城晚报全媒体记者 徐炜伦图/主办方提供6月29日下午,广州市天河区政协、天河区慈善会在员村工人...
“要把人逼疯!”八旬老人嫌自家...
6月27日报道,重庆一小区居民反映,有名老人每天清晨都到小区旁边的街心花园唱歌,居民苦不堪言:“不但...